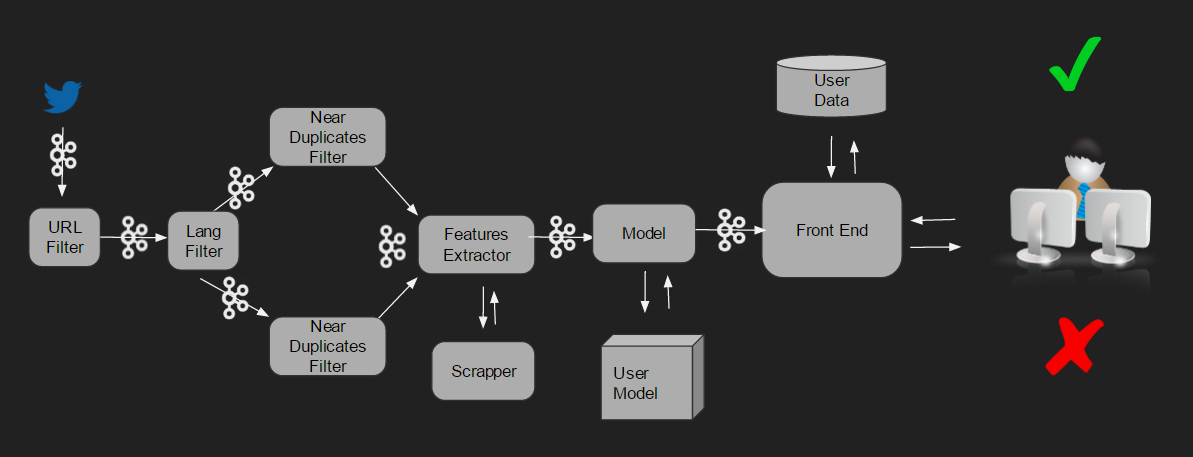
Data pipeline
The process that the data follows is the one shown in the diagram:
- The tweets are collected.
- URL Filter: the tweets are filtered excluding the ones that don’t include an URL.
- Lang Filter: the tweets are filtered by language and then separated in two groups: tweets in Spanish and tweets in English (lang_filter_ES and lang_filter_EN).
- Near Duplicates filter: each group are filtered again in order to exclude their duplicates and near duplicates.
- Features Exractor: the features of each tweet are extracted, saving them into a JSON file:
- features from the tweets.
- Scraper: features from their URLs.
- Model: the features are processed by the training model.
- User model: done with the data of the tweets labeled by the user.
- Front End: the tweets are shown to the user that label them. The data is stored in order to use it in the User model.